מבוא ל- Apache Spark
1. הקדמה
Apache Spark היא מסגרת מחשוב אשכולות קוד פתוח. הוא מספק ממשקי API פיתוח אלגנטיים עבור Scala, Java, Python ו- R המאפשרים למפתחים לבצע מגוון רחב של עומסי עבודה עתירי נתונים על פני מקורות נתונים מגוונים כולל HDFS, Cassandra, HBase, S3 וכו '.
מבחינה היסטורית, MapReduce של Hadoop התגלה כלא יעיל עבור כמה עבודות מחשוב איטרטיביות ואינטראקטיביות, מה שהוביל בסופו של דבר להתפתחות Spark. עם Spark, אנו יכולים להפעיל הגיון עד שתי סדרי גודל מהר יותר מאשר עם Hadoop בזיכרון, או סדר גודל אחד מהיר יותר בדיסק..
2. אדריכלות ניצוצות
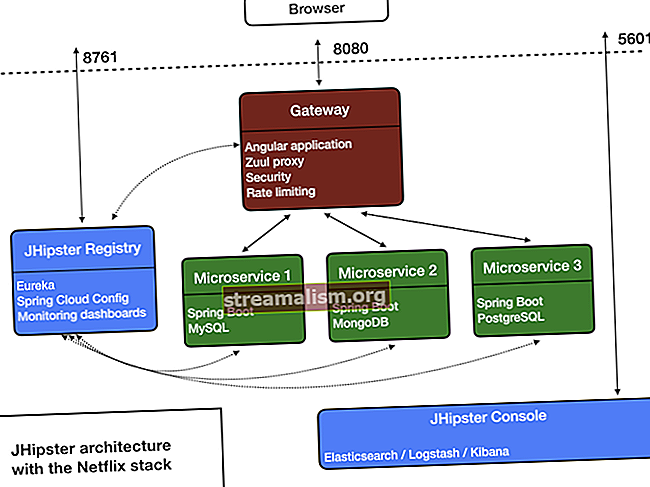
יישומי ניצוץ פועלים כקבוצות עצמאיות של תהליכים באשכול כמתואר בתרשים שלהלן:

מערך תהליכים זה מתואם על ידי SparkContext אובייקט בתוכנית הראשית שלך (נקראת תוכנית הנהג). SparkContext מתחבר למספר סוגים של מנהלי אשכולות (או מנהל האשכול העצמאי של Spark, Mesos או YARN), אשר מקצים משאבים בין יישומים.
לאחר החיבור, Spark רוכש מבצעים על צמתים באשכול, שהם תהליכים שמריצים חישובים ואוחסנים נתונים ליישום שלך.
לאחר מכן, הוא שולח את קוד היישום שלך (מוגדר על ידי קבצי JAR או Python שהועברו אליו SparkContext) למוציאים לפועל. סוף כל סוף, SparkContext שולח משימות למוציאים לפועל.
3. רכיבי ליבה
התרשים הבא נותן תמונה ברורה של המרכיבים השונים של Spark:

3.1. ליבת ניצוץ
רכיב ה- Spark Core אחראי על כל הפונקציות הבסיסיות של קלט / פלט, תזמון וניטור העבודות באשכולות ניצוץ, העברת משימות, נטוורקינג עם מערכות אחסון שונות, התאוששות תקלות וניהול זיכרון יעיל.
בניגוד ל- Hadoop, Spark נמנע מנתונים משותפים המאוחסנים בחנויות ביניים כמו Amazon S3 או HDFS באמצעות מבנה נתונים מיוחד המכונה RDD (Resilient Distributed Datasets).
ערכי נתונים מבוזרים גמישים אינם ניתנים לשינוי, אוסף מחולק של רשומות הניתנות להפעלה - במקביל ומאפשרת - חישובי 'בזיכרון' עמידים לתקלות.
RDDs תומכים בשני סוגים של פעולות:
- טרנספורמציה - טרנספורמציה של Spark RDD היא פונקציה שמייצרת RDD חדש מה- RDD הקיים. השנאי לוקח RDD כקלט ומייצר RDD אחד או יותר כפלט. טרנספורמציות הן עצלות באופיין, כלומר, הן מבוצעות כשאנחנו מכנים פעולה
- פעולה – טרנספורמציות יוצרות RDD זו מזו, אך כאשר אנו רוצים לעבוד עם מערך הנתונים בפועל, בשלב זה מבוצעת פעולה. לכן, פעולות הינן פעולות Spark RDD הנותנות ערכים שאינם RDD. ערכי הפעולה נשמרים בנהגים או במערכת האחסון החיצונית
פעולה היא אחת הדרכים לשליחת נתונים מה- Executor לנהג.
מוציאים לפועל הם סוכנים שאחראים על ביצוע משימה. בעוד שהנהג הוא תהליך JVM שמתאם עובדים וביצוע המשימה. חלק מהפעולות של Spark נספרות ואוספות.
3.2. ניצוץ SQL
Spark SQL הוא מודול Spark לעיבוד נתונים מובנים. הוא משמש בעיקר לביצוע שאילתות SQL. DataFrame מהווה את ההפשטה העיקרית עבור Spark SQL. אוסף מופץ של נתונים שהוזמנו בעמודות בעלות שם נקרא a DataFrame בספארק.
Spark SQL תומך בהבאת נתונים ממקורות שונים כמו Hive, Avro, Parquet, ORC, JSON ו- JDBC. זה גם מתכוונן לאלפי צמתים ושאילתות מרובות שעות באמצעות מנוע Spark - המספק סובלנות תקלות מלאה באמצע השאילתות.
3.3. הזרמת ניצוצות
הזרמת ניצוצות היא הרחבה של ממשק ה- API של הניצוץ המאפשר עיבוד זרם מדרגי, תפוקה גבוהה וסובלנית של תקלות של זרמי נתונים חיים. ניתן להטמיע נתונים ממספר מקורות, כגון שקעי קפקא, Flume, Kinesis או TCP.
לבסוף ניתן לדחוף נתונים מעובדים למערכות קבצים, מסדי נתונים ולוחות מחוונים חיים.
3.4. ניצוץ מליב
MLlib היא ספריית הלמידה החישובית (ML) של ספארק. מטרתה היא להפוך את למידת המכונה המעשית להרחבה וקלה. ברמה גבוהה הוא מספק כלים כגון:
- אלגוריתמים של ML - אלגוריתמי למידה נפוצים כגון סיווג, רגרסיה, אשכולות וסינון שיתופי
- תכונה - מיצוי תכונות, טרנספורמציה, צמצום ממדיות ובחירה
- צינורות - כלים לבניית, הערכה וכוונון צינורות ML
- התמדה - חיסכון וטעינה של אלגוריתמים, מודלים וצינורות
- כלי עזר - אלגברה לינארית, סטטיסטיקה, טיפול בנתונים וכו '.
3.5. Spark GraphX
GraphX הוא רכיב עבור גרפים וחישובים מקבילים לגרף. ברמה גבוהה, GraphX מרחיב את ה- Spark RDD על ידי הצגת הפשטת גרף חדשה: מולטיגרף מכוון עם מאפיינים המחוברים לכל קודקוד וקצה.
כדי לתמוך בחישוב גרפי, GraphX חושף קבוצה של אופרטורים בסיסיים (למשל, תצלום, joinVertices, ו aggregateMessages).
בנוסף, GraphX כולל אוסף הולך וגדל של אלגוריתמים של גרפים ובונים לפשט משימות ניתוח גרפים.
4. "שלום עולם" בספארק
כעת, לאחר שהבנו את מרכיבי הליבה, נוכל לעבור לפרויקט פשוט מבוסס Maven מבוסס Maven - לחישוב ספירת מילים.
נדגים את ניצוץ הריצה במצב המקומי בו כל הרכיבים פועלים באופן מקומי על אותה מכונה בה מדובר בצומת הראשי, בצמתים המבצעים או במנהל האשכול העצמאי של ספארק.
4.1. הגדרת Maven
בואו נקים פרויקט Java Maven עם תלות הקשורה ל- Spark pom.xml קוֹבֶץ:
org.apache.spark spark-core_2.10 1.6.0 4.2. ספירת מילים - עבודת ניצוץ
בואו נכתוב כעת עבודת ספארק לעיבוד קובץ המכיל משפטים והפקת מילים מובחנות וספירתם בקובץ:
ראשי ריק סטטי ציבורי (String [] args) זורק Exception {if (args.length <1) {System.err.println ("שימוש: JavaWordCount"); System.exit (1); } SparkConf sparkConf = SparkConf חדש (). SetAppName ("JavaWordCount"); JavaSparkContext ctx = JavaSparkContext חדש (sparkConf); שורות JavaRDD = ctx.textFile (args [0], 1); מילות JavaRDD = lines.flatMap (s -> Arrays.asList (SPACE.split (s)). Iterator ()); אחד JavaPairRDD = מילים. MapToPair (מילה -> Tuple2 חדש (מילה, 1)); ספירת JavaPairRDD = ones.reduceByKey ((שלם i1, שלם i2) -> i1 + i2); רשימה פלט = counts.collect (); עבור (Tuple2 tuple: output) {System.out.println (tuple._1 () + ":" + tuple._2 ()); } ctx.stop (); } שימו לב שאנו מעבירים את הנתיב של קובץ הטקסט המקומי כוויכוח לעבודת Spark.
א SparkContext אובייקט הוא נקודת הכניסה העיקרית עבור Spark ומייצג את החיבור לאשכול Spark שכבר פועל. זה משתמש SparkConf אובייקט לתיאור תצורת היישום. SparkContext משמש לקריאת קובץ טקסט בזיכרון כ- JavaRDD לְהִתְנַגֵד.
לאחר מכן, אנו הופכים את הקווים JavaRDD להתנגד למילים JavaRDD אובייקט באמצעות מפות שטוחות שיטה להמיר תחילה כל שורה למילים המופרדות ברווח ואז לשטח את הפלט של כל עיבוד שורה.
אנו מחילים שוב פעולת טרנספורמציה mapToPair שבעצם ממפה כל הופעה של המילה לכפל המילים וספירה של 1.
לאחר מכן, אנו מיישמים את להפחית ByKey פעולה לקיבוץ מספר מופעים של כל מילה בספירה 1 לכדי מילים וסיכמה את הספירה.
לבסוף, אנו מבצעים גאלקט פעולת RDD להשגת התוצאות הסופיות.
4.3. ביצוע - ניצוץ איוב
בואו עכשיו לבנות את הפרויקט באמצעות Maven כדי ליצור apache-spark-1.0-SNAPSHOT.jar בתיקיית היעד.
לאחר מכן, עלינו להגיש את עבודת WordCount הזו ל- Spark:
$ {spark-install-dir} / bin / spark-submit --class com.baeldung.WordCount - master local $ {WordCount-MavenProject} /target/apache-spark-1.0-SNAPSHOT.jar $ {WordCount-MavenProject} /src/main/resources/spark_example.txtיש לעדכן את ספריית ההתקנה של ניצוצות ואת ספריית הפרויקטים של WordCount Maven לפני הפעלת מעל הפקודה.
בהגשה כמה צעדים קורים מאחורי הקלעים:
- מקוד הנהג, SparkContext מתחבר למנהל אשכולות (במקרה שלנו נוצר מנהל אשכולות עצמאי הפועל באופן מקומי)
- מנהל אשכולות מקצה משאבים בין היישומים האחרים
- ספארק רוכש מנהלים על צמתים באשכול. כאן, יישום ספירת המילים שלנו יקבל תהליכי ביצוע משלו
- קוד יישום (קבצי jar) נשלח למבצעים
- המשימות נשלחות על ידי SparkContext למוציאים לפועל.
לבסוף, התוצאה של עבודת הניצוץ מוחזרת לנהג ונראה את ספירת המילים בקובץ כפלט:
שלום 1 מתוך 2 Baledung 2 שמור 1 למידה 1 ניצוץ 1 ביי 15. מסקנה
במאמר זה דנו בארכיטקטורה ובמרכיבים השונים של Apache Spark. הדגמנו גם דוגמא לעבודה של עבודת Spark שנותנת ספירת מילים מקובץ.
כמו תמיד, קוד המקור המלא זמין ב- GitHub.