בניית צינור נתונים עם קפקא, הזרמת ניצוצות וקסנדרה
1. סקירה כללית
אפאצ'י קפקא היא פלטפורמה ניתנת להרחבה, ביצועים גבוהים, עם חביון נמוך מאפשר קריאה וכתיבה של זרמי נתונים כמו מערכת העברת הודעות. אנחנו יכולים להתחיל עם קפקא בג'אווה די בקלות.
הזרמת ניצוצות היא חלק מפלטפורמת Apache Spark ש- מאפשר עיבוד מדרגי, תפוקה גבוהה ועמיד בפני תקלות בזרמי נתונים. למרות שכתוב ב- Scala, Spark מציע ממשקי API של Java לעבודה.
אפאצ'י קסנדרה הוא א מאגר נתונים NoSQL מופץ ורחב עמודות. פרטים נוספים על קסנדרה זמינים במאמר הקודם שלנו.
במדריך זה, נשלב את אלה ליצירת צינור נתונים מדרגי ביותר וסובלני לתקלות עבור זרם נתונים בזמן אמת.
2. התקנות
כדי להתחיל, נצטרך להתקין מקפה, ספארק וקאסנדרה באופן מקומי במחשב שלנו כדי להריץ את היישום. נראה כיצד לפתח צינור נתונים באמצעות פלטפורמות אלה ככל שנלך.
עם זאת, נעזוב את כל תצורות ברירת המחדל כולל יציאות לכל ההתקנות אשר יסייעו בהדרכת ההדרכה בצורה חלקה.
2.1. קפקא
התקנת קפקא במחשב המקומי שלנו היא פשוטה למדי וניתן למצוא אותה כחלק מהתיעוד הרשמי. נשתמש במהדורת 2.1.0 של קפקא.
בנוסף, קפקא דורש מאפצ'י זואיפר לרוץ אך לצורך הדרכה זו, ננצל את מופע ה- Zookeeper הצומת היחיד הארוז עם Kafka.
לאחר שהצלחנו להפעיל את Zookeeper ו- Kafka באופן מקומי בעקבות המדריך הרשמי, נוכל להמשיך וליצור את הנושא שלנו בשם "הודעות":
$ KAFKA_HOME $ \ bin \ windows \ kafka-topics.bat - צור \ - zookeeper localhost: 2181 \ - גורם שכפול 1 - מחיצות 1 \ - הודעות נושאשים לב כי התסריט הנ"ל מיועד לפלטפורמת Windows, אך ישנם סקריפטים דומים זמינים גם לפלטפורמות דומות ל- Unix.
2.2. לְעוֹרֵר
Spark משתמש בספריות הלקוחות של Hadoop עבור HDFS ו- YARN. כתוצאה מכך, זה יכול להיות מאוד מסובך להרכיב את הגרסאות התואמות של כל אלה. עם זאת, ההורדה הרשמית של Spark מגיעה ארוזה מראש עם גרסאות פופולריות של Hadoop. לצורך הדרכה זו נשתמש בחבילת גרסה 2.3.0 "שנבנתה מראש עבור Apache Hadoop 2.7 ואילך".
לאחר החבילה הנכונה של Spark נפרקת, ניתן להשתמש בתסריטים הזמינים להגשת בקשות. נראה זאת בהמשך כשנפתח את היישום שלנו באביב אתחול.
2.3. קסנדרה
DataStax מעמידה מהדורה קהילתית של קסנדרה לפלטפורמות שונות כולל Windows. אנו יכולים להוריד ולהתקין זאת במחשב המקומי שלנו בקלות רבה בעקבות התיעוד הרשמי. נשתמש בגרסה 3.9.0.
לאחר שהצלחנו להתקין ולהפעיל את קסנדרה במחשב המקומי שלנו, נוכל להמשיך ליצור את מרחב המפתחות והשולחן שלנו. ניתן לעשות זאת באמצעות מעטפת CQL המשלחת עם ההתקנה שלנו:
צור אוצר מילים של KEYSPACE עם REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1}; אוצר מילים USE; צור מילים בטבלה (טקסט של המילה מפתח ראשי, ספירה int);שים לב שיצרנו מרחב שמות בשם אוצר מילים ושולחן בו נקרא מילים עם שתי עמודות, מִלָה, ו לספור.
3. תלות
אנו יכולים לשלב תלות בקפה וספארק ביישום שלנו באמצעות Maven. אנו נשלוף את התלות הללו ממייבן סנטרל:
- ניצוץ הליבה
- ניצוץ SQL
- סטרימינג ספארק
- סטרימינג של קפקא ספארק
- קסנדרה ספארק
- קסנדרה ג'אווה ספארק
ונוכל להוסיף אותם לפום שלנו בהתאם:
org.apache.spark spark-core_2.11 2.3.0 סיפק org.apache.spark spark-sql_2.11 2.3.0 סיפק org.apache.spark ניצוץ-streaming_2.11 2.3.0 סיפק org.apache.spark ניצוץ -kafka-0-10_2.11 2.3.0 com.datastax.spark spark-cassandra-connector_2.11 2.3.0 com.datastax.spark spark-cassandra-connector-java_2.11 1.5.2 שים לב שחלק מהתלות הללו מסומנות כ- בתנאי בהיקף. הסיבה לכך היא שאלה יהיו זמינים על ידי התקנת Spark שם נגיש את הבקשה לביצוע באמצעות ניצוץ-הגשה.
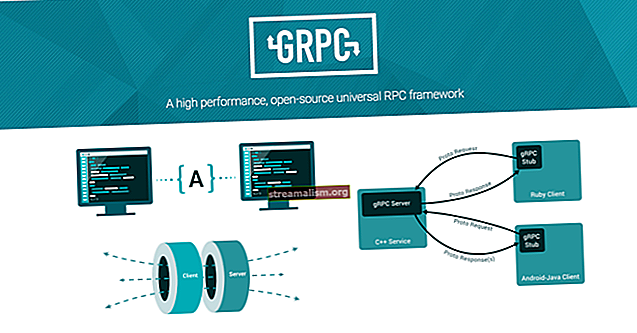
4. הזרמת ניצוצות - אסטרטגיות אינטגרציה של קפקא
בשלב זה, כדאי לדבר בקצרה על אסטרטגיות האינטגרציה של ספארק וקפקא.
קפקא הציג ממשק API חדש לצרכן בין גרסאות 0.8 ל- 0.10. לפיכך, חבילות הזרמת הניצוץ המתאימות זמינות עבור שתי גרסאות הברוקר. חשוב לבחור את החבילה המתאימה בהתאם למתווך הזמין והתכונות הרצויות.
4.1. ניצוץ זורם קפקא 0.8
גרסת ה- 0.8 היא ממשק ה- API לאינטגרציה יציבה עם אפשרויות שימוש מבוסס מקלט או גישה ישירה. לא נפרט על הגישות הללו שנוכל למצוא בתיעוד הרשמי. נקודה חשובה שיש לציין כאן היא שחבילה זו תואמת לגרסאות Kafka Broker 0.8.2.1 ומעלה.
4.2. ניצוץ ניצוץ קפקא 0.10
זה כרגע במצב ניסיוני ותואם לגרסאות Kafka Broker 0.10.0 ומעלה בלבד. חבילה זו מציע את הגישה הישירה בלבד, ועושה כעת שימוש בממשק ה- API הצרכני החדש של קפקא. אנו יכולים למצוא פרטים נוספים על כך בתיעוד הרשמי. חשוב לציין, שכן לא תואם לאחור לגרסאות ישנות יותר של Kafka Broker.
שים לב כי לצורך הדרכה זו, נשתמש בחבילת 0.10. התלות שהוזכרה בסעיף הקודם מתייחסת לכך בלבד.
5. פיתוח צינור נתונים
ניצור יישום פשוט ב- Java באמצעות Spark שישתלב עם נושא קפקא שיצרנו קודם. היישום יקרא את ההודעות כפי שפורסמו וימפור את תדירות המילים בכל הודעה. לאחר מכן זה יעודכן בטבלת קסנדרה שיצרנו קודם.
בואו נתאר במהירות כיצד הנתונים יזרמו:

5.1. מקבל JavaStreamingContext
ראשית, נתחיל באתחול ה- JavaStreamingContext המהווה נקודת כניסה לכל יישומי ה- Streaming של ניצוצות:
SparkConf sparkConf = SparkConf חדש (); sparkConf.setAppName ("WordCountingApp"); sparkConf.set ("spark.cassandra.connection.host", "127.0.0.1"); JavaStreamingContext streamingContext = JavaStreamingContext חדש (sparkConf, Durations.seconds (1));5.2. מקבל DStream מקפקא
כעת אנו יכולים להתחבר לנושא קפקא מה- JavaStreamingContext:
מפה kafkaParams = HashMap חדש (); kafkaParams.put ("bootstrap.servers", "localhost: 9092"); kafkaParams.put ("key.deserializer", StringDeserializer.class); kafkaParams.put ("value.deserializer", StringDeserializer.class); kafkaParams.put ("group.id", "use_a_separate_group_id_for_each_stream"); kafkaParams.put ("auto.offset.reset", "האחרון"); kafkaParams.put ("enable.auto.commit", שקר); נושאי האוסף = Arrays.asList ("הודעות"); JavaInputDStream הודעות = KafkaUtils.createDirectStream (streamingContext, LocationStrategies.PreferConsistent (), ConsumerStrategies. הירשם (נושאים, kafkaParams)); שים לב שעלינו לספק כאן desalizer עבור מפתח וערך. לסוגי נתונים נפוצים כמו חוּט, ה- deserializer זמין כברירת מחדל. עם זאת, אם ברצוננו לאחזר סוגי נתונים מותאמים אישית, נצטרך לספק מורשי ערכות מותאמים אישית.
הנה, השגנו JavaInputDStream שהוא יישום של זרמים מבוזרים או DStreams, ההפשטה הבסיסית שמספק ספארק סטרימינג. באופן פנימי DStreams אינו אלא סדרה מתמשכת של RDD.
5.3. העיבוד הושג DStream
כעת נבצע סדרה של פעולות ב- JavaInputDStream כדי להשיג תדרי מילים בהודעות:
תוצאות JavaPairDStream = הודעות .mapToPair (רשומה -> Tuple2 חדש (record.key (), record.value ())); קווי JavaDStream = תוצאות .מפה (tuple2 -> tuple2._2 ()); מילות JavaDStream = שורות .flatMap (x -> Arrays.asList (x.split ("\ s +")). Iterator ()); JavaPairDStream wordCounts = מילים .mapToPair (s -> Tuple2 חדש (s, 1)) .reduceByKey ((i1, i2) -> i1 + i2);5.4. עיבוד מתמיד DStream אל קסנדרה
לבסוף, אנו יכולים לחזור על המעובד JavaPairDStream להכניס אותם לשולחן קסנדרה שלנו:
wordCounts.foreachRDD (javaRdd -> {מפה wordCountMap = javaRdd.collectAsMap (); עבור (מפתח מחרוזת: wordCountMap.keySet ()) {רשימה wordList = Arrays.asList (מילה חדשה (מפתח, wordCountMap.get (מפתח))); JavaRDD rdd = streamingContext.sparkContext (). מקביל (wordList); javaFunctions (rdd) .writerBuilder ("אוצר מילים", "מילים", mapToRow (Word.class)). SaveToCassandra ();}});5.5. הפעלת האפליקציה
מכיוון שמדובר ביישום לעיבוד זרם, נרצה להמשיך לפעול:
streamingContext.start (); streamingContext.awaitTermination ();6. מינוף מחסומים
ביישום לעיבוד זרם, לעתים קרובות זה שימושי לשמור על מצב בין קבוצות נתונים המעובדות.
לדוגמא, בניסיון הקודם שלנו, אנו מסוגלים לאחסן רק את התדירות הנוכחית של המילים. מה אם נרצה לאחסן את התדירות המצטברת במקום זאת? הזרמת ניצוצות מאפשרת באמצעות מושג הנקרא מחסומים.
כעת נשנה את הצינור שיצרנו קודם כדי למנף נקודות מחסום:

לידיעתך, נשתמש במחסומים רק למפגש של עיבוד נתונים. זה לא מספק סובלנות לתקלות. עם זאת, ניתן להשתמש במחסום גם לסובלנות תקלות.
יש כמה שינויים שנצטרך לבצע ביישום שלנו כדי למנף נקודות מחסום. זה כולל מתן JavaStreamingContext עם מיקום מחסום:
streamingContext.checkpoint ("./. מחסום");כאן אנו משתמשים במערכת הקבצים המקומית לאחסון נקודות ביקורת. עם זאת, למען החוסן, יש לאחסן זאת במיקום כמו HDFS, S3 או Kafka. מידע נוסף על כך זמין בתיעוד הרשמי.
לאחר מכן, נצטרך להביא את נקודת הבידוק וליצור ספירה מצטברת של מילים תוך כדי עיבוד כל מחיצה באמצעות פונקציית מיפוי:
JavaMapWithStateDStream cumulativeWordCounts = wordCounts .mapWithState (StateSpec.function ((word, one, state) -> {int sum = one.orElse (0) + (state.exists ()? state.get (): 0); פלט Tuple2 = חדש Tuple2 (מילה, סכום); state.update (סכום); פלט החזרה;})); ברגע שנקבל את ספירת המילים המצטברות, נוכל להמשיך לאתר ולשמור אותם בקסנדרה כמו בעבר.
שימו לב כי בזמן בדיקת נתונים שימושית לעיבוד מלכותי, והיא כוללת עלות חביון. לפיכך, יש צורך להשתמש בזה בחוכמה יחד עם מרווח בדיקות אופטימלי.
7. הבנת קיזוזים
אם נזכור כמה מהפרמטרים של קפקא שקבענו קודם:
kafkaParams.put ("auto.offset.reset", "האחרון"); kafkaParams.put ("enable.auto.commit", שקר);אלה בעצם מתכוונים לכך איננו רוצים להתחייב אוטומטית לקיזוז ונרצה לבחור בקיזוז האחרון בכל פעם שמתבצעת אתחול של קבוצת צרכנים. כתוצאה מכך, היישום שלנו יוכל לצרוך הודעות שפורסמו רק במהלך התקופה שהיא פועלת.
אם ברצוננו לצרוך את כל ההודעות שפורסמו ללא קשר לשאלה האם היישום רץ או לא ורוצה לעקוב אחר ההודעות שכבר פורסמו נצטרך להגדיר את הקיזוז כראוי יחד עם שמירת מצב הקיזוז, למרות שזה קצת מחוץ לתחום עבור הדרכה זו.
זוהי גם דרך בה ניצוץ ניצוצות מציע רמת אחריות מסוימת כמו "בדיוק פעם אחת". זה בעצם אומר שכל הודעה שפורסמה בנושא קפקא תעבד רק פעם אחת בדיוק על ידי ניצוץ ניצוצות.
8. פריסת יישום
אנחנו יכולים לפרוס את היישום שלנו באמצעות סקריפט הגשת הניצוץ שמגיע ארוז מראש עם התקנת Spark:
$ SPARK_HOME $ \ bin \ spark-submit \ --class com.baeldung.data.pipeline.WordCountingAppWithCheckpoint \ - master local [2] \ target \ spark-streaming-app-0.0.1-SNAPSHOT-jar-with-dependencies .קַנקַןשים לב כי הצנצנת שאנו יוצרים באמצעות Maven צריכה להכיל את התלות שאינן מסומנות כ- בתנאי בהיקף.
ברגע שאנו מגישים בקשה זו ונפרסם כמה הודעות בנושא קפקא שיצרנו קודם, עלינו לראות את ספירת המילים המצטברות שמתפרסמות בטבלת קסנדרה שיצרנו קודם.
9. מסקנה
לסיכום, במדריך זה למדנו כיצד ליצור צינור נתונים פשוט באמצעות Kafka, Spark Streaming ו- Cassandra. למדנו גם כיצד למנף מחסומים בזרם ניצוצות כדי לשמור על מצב בין קבוצות.
כמו תמיד, הקוד לדוגמאות זמין ב- GitHub.