מערכת המלצות לסינון שיתופי ב- Java
1. הקדמה
במדריך זה נלמד הכל על אלגוריתם Slope One בג'אווה.
נציג גם את יישום הדוגמה לבעיה של סינון שיתופי (CF) - טכניקת למידת מכונה משמש מערכות המלצה.
זה יכול לשמש, למשל, כדי לחזות תחומי עניין של משתמשים עבור פריטים ספציפיים.
2. סינון שיתופי
האלגוריתם Slope One הוא מערכת סינון שיתופית מבוססת פריטים. המשמעות היא שהיא מבוססת לחלוטין על דירוג פריט המשתמש. כאשר אנו מחשבים את הדמיון בין אובייקטים, אנו מכירים רק את היסטוריית הדירוגים, ולא את התוכן עצמו. דמיון זה משמש אז לחיזוי דירוגי משתמשים פוטנציאליים עבור זוגות פריטי משתמש שאינם קיימים במערך הנתונים.
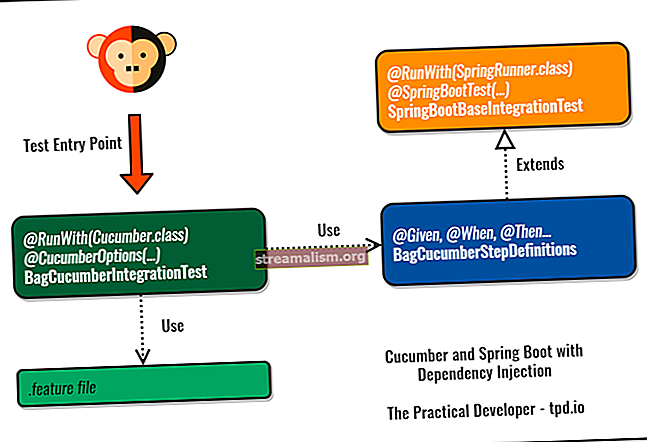
התמונה למטה מציגה את התהליך המלא לקבלת וחישוב הדירוג עבור המשתמש הספציפי:

בהתחלה, משתמשים מדרגים פריטים שונים במערכת. לאחר מכן, האלגוריתם מחשב את הדמיון. לאחר מכן, המערכת מבצעת חיזויים לדירוג פריטי משתמש, אותם המשתמש עדיין לא דירג.
לפרטים נוספים בנושא הסינון השיתופי, אנו יכולים להתייחס למאמר בויקיפדיה.
3. האלגוריתם מדרון אחד
מדרון אחד נקרא כצורה הפשוטה ביותר של סינון שיתופי מבוסס פריט לא טריוויאלי על סמך דירוגים. זה לוקח בחשבון הן מידע מכל המשתמשים שדירגו את אותו פריט והן משאר הפריטים שדורגו על ידי אותו משתמש כדי לחשב את מטריצת הדמיון.
בדוגמה הפשוטה שלנו, אנו הולכים לחזות דירוג משתמשים על הפריטים בחנות.
נתחיל במודל Java פשוט לבעיה ולתחום שלנו.
3.1. דגם ג'אווה
במודל שלנו יש לנו שני אובייקטים עיקריים - פריטים ומשתמשים. ה פריט מחלקה מכילה את שם הפריט:
פריט מחרוזת פריט שם;מצד שני, ה מִשׁתַמֵשׁ הכיתה מכילה את שם המשתמש:
שם משתמש פרטי מחרוזת;לבסוף, יש לנו InputData מחלקה שתשמש לאתחול הנתונים. נניח שניצור חמישה מוצרים שונים בחנות:
פריטי רשימה = Arrays.asList (פריט חדש ("ממתק"), פריט חדש ("שתייה"), פריט חדש ("סודה"), פריט חדש ("פופקורן"), פריט חדש ("חטיפים"));יתר על כן, ניצור שלושה משתמשים שדירגו באופן אקראי חלק מהאמור לעיל באמצעות הסולם מ 0.0-1.0, כאשר 0 לא אומר עניין, 0.5 איכשהו מעוניין ו- 1.0 פירושו מעוניין לחלוטין. כתוצאה מאתחול נתונים נקבל מַפָּה עם נתוני דירוג פריטי המשתמש:
מַפָּה נתונים; 3.2. מטריצות הבדלים ותדרים
על סמך הנתונים הזמינים נחשב את היחסים בין הפריטים, כמו גם את מספר המופעים של הפריטים. עבור כל משתמש אנו בודקים את דירוג הפריטים שלו:
עבור (משתמש HashMap: data.values ()) {עבור (ערך e: user.entrySet ()) {// ...}}בשלב הבא, אנו בודקים אם הפריט קיים במטריצות שלנו. אם זו תופעה ראשונה, אנו יוצרים את הערך החדש במפות:
אם (! diff.containsKey (e.getKey ())) {diff.put (e.getKey (), HashMap חדש ()); freq.put (e.getKey (), HashMap חדש ()); } המטריצה הראשונה משמשת לחישוב ההבדלים בין דירוג המשתמשים. הערכים שלו עשויים להיות חיוביים או שליליים (מכיוון שההבדל בין דירוגים עשוי להיות שלילי), והם מאוחסנים כ- לְהַכפִּיל. מצד שני, התדרים מאוחסנים כ- מספר שלם ערכים.
בשלב הבא אנו הולכים להשוות את הדירוגים של כל הפריטים:
עבור (ערך e2: user.entrySet ()) {int oldCount = 0; אם (freq.get (e.getKey ()). containKey (e2.getKey ())) {oldCount = freq.get (e.getKey ()). קבל (e2.getKey ()). intValue (); } oldDiff כפול = 0.0; אם (diff.get (e.getKey ()). containKey (e2.getKey ())) {oldDiff = diff.get (e.getKey ()). get (e2.getKey ()). doubleValue (); } תצפית כפולה = e.getValue () - e2.getValue (); freq.get (e.getKey ()). put (e2.getKey (), oldCount + 1); diff.get (e.getKey ()). לשים (e2.getKey (), oldDiff + נצפה Diff); }אם מישהו דירג את הפריט לפני כן, אנו מגדילים את ספירת התדרים באחד. יתר על כן, אנו בודקים את ההפרש הממוצע בין דירוגי הפריט ומחושבים את החדש הבחין בדיף.
שימו לב, שאנחנו שמים את הסכום של oldDiff ו הבחין בדיף כערך חדש של פריט.
לבסוף, אנו מחשבים את ציוני הדמיון בתוך המטריצות:
עבור (פריט j: diff.keySet ()) {for (פריט i: diff.get (j) .keySet ()) {OldValue כפול = diff.get (j) .get (i) .doubleValue (); ספירת int = freq.get (j) .get (i) .intValue (); diff.get (j) .put (i, oldValue / count); }}ההיגיון העיקרי הוא לחלק את ההבדל בין דירוג הפריט המחושב למספר המופעים שלו. לאחר שלב זה, אנו יכולים להדפיס את מטריצת ההבדלים הסופית שלנו.
3.3. תחזיות
כחלק העיקרי של Slope One, אנו הולכים לחזות את כל הדירוגים החסרים על סמך הנתונים הקיימים. על מנת לעשות זאת, עלינו להשוות את דירוג פריטי המשתמש למטריצת ההבדלים שחושבה בשלב הקודם:
עבור (כניסה e: data.entrySet ()) {for (Item j: e.getValue (). keySet ()) {for (Item k: diff.keySet ()) {double predictedValue = diff.get (k). get (j ) .doubleValue () + e.getValue (). get (j) .doubleValue (); כפול finalValue = predictedValue * freq.get (k) .get (j) .intValue (); uPred.put (k, uPred.get (k) + finalValue); uFreq.put (k, uFreq.get (k) + freq.get (k) .get (j) .intValue ()); }} // ...} לאחר מכן, עלינו להכין את התחזיות "הנקיות" באמצעות הקוד שלהלן:
HashMap נקי = HashMap חדש (); עבור (פריט j: uPred.keySet ()) {אם (uFreq.get (j)> 0) {clean.put (j, uPred.get (j). doubleValue () / uFreq.get (j) .intValue ( )); }} עבור (פריט j: InputData.items) {if (e.getValue (). containKey (j)) {clean.put (j, e.getValue (). get (j)); } אחר אם (! clean.containsKey (j)) {clean.put (j, -1.0); }}הטריק שיש לקחת בחשבון עם מערך נתונים גדול יותר הוא להשתמש רק בערכי הפריטים בעלי ערך תדר גדול (לדוגמא> 1). שימו לב, אם החיזוי אינו אפשרי, הערך שלו יהיה שווה ל- -1.
לסיום, הערה חשובה מאוד. אם האלגוריתם שלנו עבד כראוי, עלינו לקבל את התחזיות לפריטים שהמשתמש לא דרג, אך גם את הדירוגים החוזרים על הפריטים שהוא דירג. דירוגים חוזרים ונשנים אלה לא אמורים להשתנות, אחרת זה אומר שיש באג ביישום האלגוריתם שלך.
3.4. טיפים
ישנם כמה גורמים עיקריים המשפיעים על אלגוריתם Slope One. להלן מספר עצות כיצד להגדיל את הדיוק וזמן העיבוד:
- שקול להשיג את דירוג פריטי המשתמש בצד ה- DB עבור ערכות נתונים גדולות
- הגדר את מסגרת הזמן לאיסוף דירוגים, מכיוון שאינטרסים של אנשים עשויים להשתנות עם הזמן - זה גם יקטין את הזמן הדרוש לעיבוד נתוני קלט
- פצל מערכי נתונים גדולים לקבצים קטנים יותר - אינך צריך לחשב חיזויים לכל המשתמשים מדי יום; אתה יכול לבדוק אם המשתמש התקשר עם הפריט החזוי ואז להוסיף / להסיר אותו מתור העיבוד למחרת
4. מסקנה
במדריך זה הצלחנו ללמוד על אלגוריתם Slope One. יתר על כן, הצגנו את בעיית הסינון השיתופי למערכות המלצות על פריטים.
ה יישום מלא של מדריך זה ניתן למצוא בפרויקט GitHub.